Overview
Introduction to STADLE
STADLE is a paradigm-shifting, intelligence-centric platform for federated, collaborative, and continuous learning. STADLE stands for Scalable Traceable Adaptive Distributed Learning Environment.
At its core, STADLE provides federated learning capabilities, enabling the continuous collection of machine learning models from distributed devices or clients, aggregation of their collective intelligence, and redistribution back to the local devices.
Federated Learning (FL) through STADLE addresses key challenges commonly encountered in traditional machine learning systems:
Privacy: FL eliminates the need to upload raw data to cloud servers, preserving user privacy by ensuring personal or sensitive data remains local.
Learning Efficiency: Training massive centralized datasets can be highly inefficient. With a distributed framework like FL, STADLE leverages dispersed resources to speed up and reduce the cost of learning.
Real-Time Intelligence: Traditional AI systems often suffer from delays that reduce the value of insights. FL, by avoiding heavy data pipelines and relying on local computation, enables faster delivery of high-quality intelligence.
Communication Load: FL significantly reduces traffic compared to traditional systems by exchanging model parameters instead of raw data.
Low Latency: By employing decentralized FL servers at the edge, STADLE minimizes the delay in obtaining collective intelligence.
STADLE enhances FL through a horizontally designed architecture that improves:
Scalability: Decentralized FL servers in STADLE balance the load, allowing more users and eliminating the need for a central aggregator by using semi-global models.
Traceability: The platform includes performance tracking tools that monitor and manage the evolution of intelligence models across the decentralized system.
Usability: Our SaaS platform (https://stadle.ai) provides a user-friendly GUI to monitor distributed learning, manage aggregators and agents, and control operations intuitively.
Resiliency: In real-world scenarios, system failures and network disconnections are common. STADLE ensures continuous learning even in such conditions.
Adaptability: Unlike static intelligence from big data systems, STADLE’s adaptive intelligence remains current by continuously syncing local and global models through resilient distributed learning.
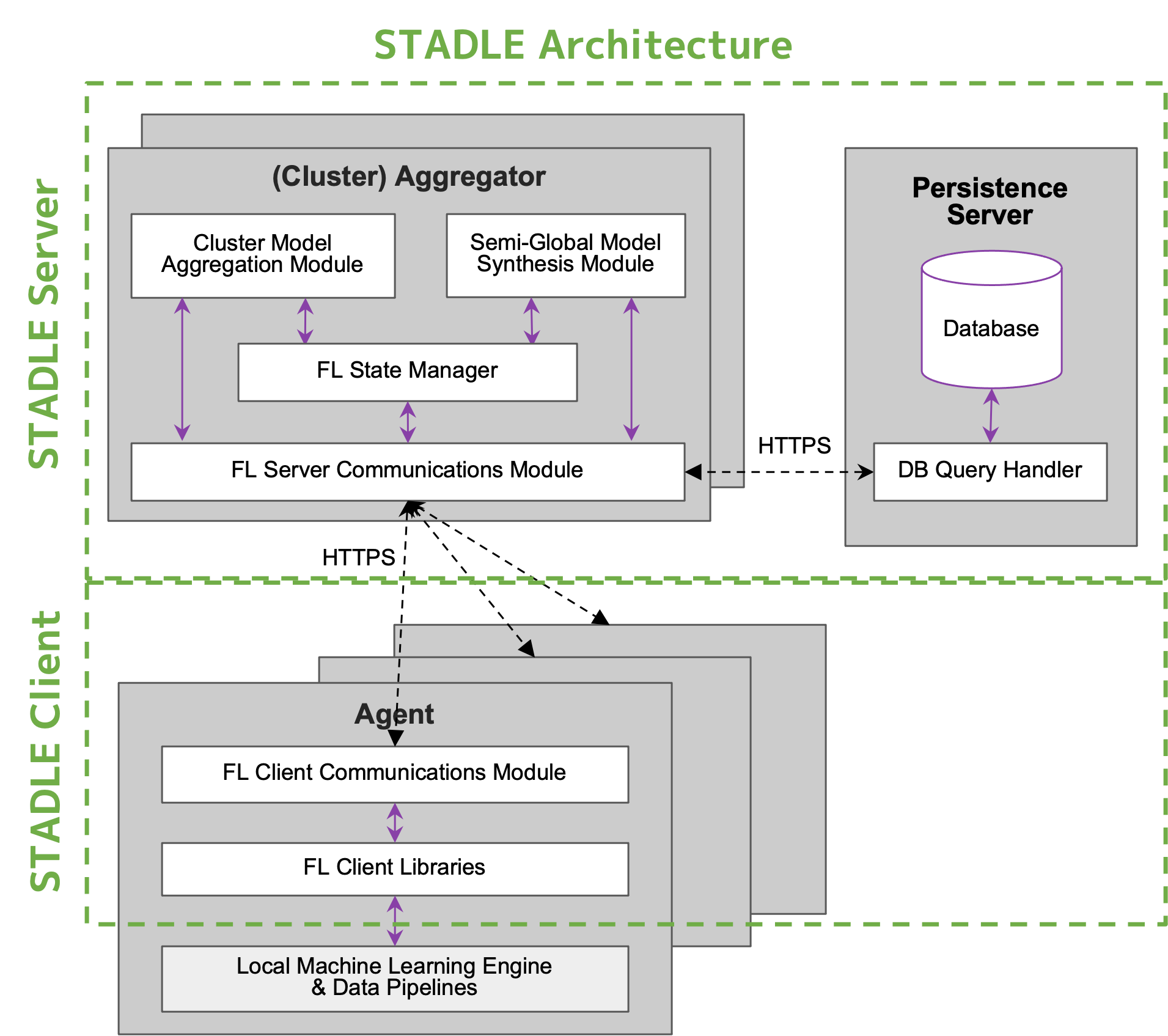
STADLE Architecture
STADLE consists of three main components:
Persistence Server - Maintains various database entries and ML models.
(Cluster) Aggregator - Serves as the core FL server, receiving ML models from distributed agents and performing model aggregation.
(Distributed) Agent - A set of libraries and tools that integrate local ML engines/models into the STADLE platform. - Communicates with STADLE’s core functions. - Available through the stadle-client library. Usage in code:
from stadle import BasicClient - BasicClient integrates training, testing, and validation functions of the local ML process.
All components communicate over HTTPS and exchange ML models securely.
Initial Base Model Upload Process
The first step in the federated learning process is uploading the initial ML model, referred to as the Base Model.
This model architecture is shared across all aggregators and agents throughout the entire process. The agent responsible for uploading the base model is known as the admin agent.
The base model includes the model file itself along with metadata such as format (e.g., PyTorch), creation time, and initial performance.
It also acts as the first semi-global model (SG model), which other agents can download.
This registration is typically performed only once unless the FL process is restarted from scratch.
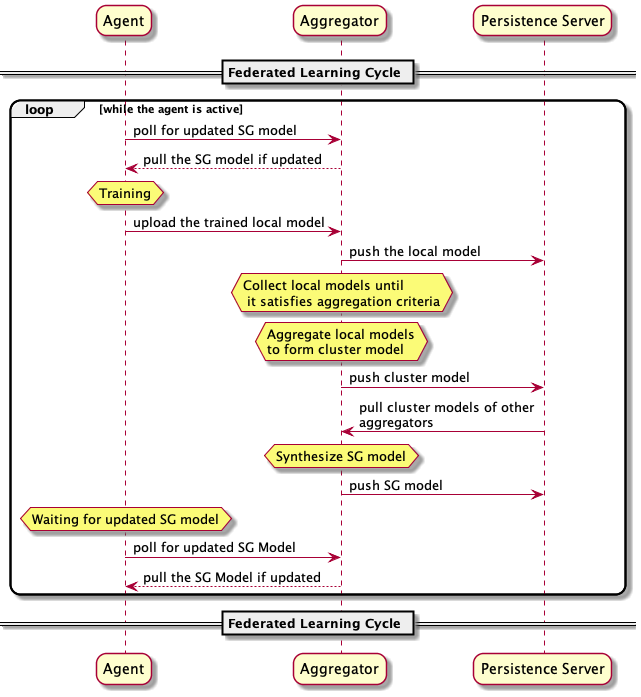
Federated Learning Cycle with STADLE
The diagram below illustrates the federated learning cycle between an aggregator and an agent. While the example shows a single agent, in practice, many agents are distributed across devices.
Agents request the global model (an updated federated model), train it locally with new data, and deploy it to their own applications.
After receiving the global model, the agent begins local training using newly collected data — which is never sent to the aggregator.
Once training is complete, the agent sends the updated local model back to the aggregator using the FL client API.
The aggregator:
Receives and stores local models in the database.
Collects models until the current FL round is complete (based on a defined threshold).
Aggregates models to generate a cluster global model.
Optionally, collaborates with other aggregators to produce a semi-global (SG) model, which is then sent to agents.
If only one aggregator exists, the SG model is equivalent to the cluster model.
Agents continuously poll the aggregator to check for SG model availability. When the SG model is ready, it’s sent back to agents for retraining.
This cycle repeats indefinitely unless explicitly terminated.
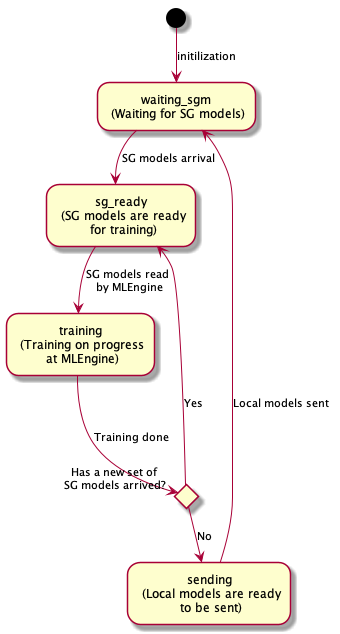
Client-Side Local Training Cycle
Understanding the agent’s state transitions helps in integrating STADLE into your ML applications.
Below is the local training lifecycle of an agent:
`waiting_sgm`: The agent polls the aggregator for SG model updates at a defined interval.
`sg_ready`: Once available, the SG model is downloaded. The agent may also gather and store input/output pairs for training.
`training`: Local retraining begins using the SG model. If a new SG model arrives during training, the agent discards the current model and returns to sg_ready.
`sending`: Upon completion, the updated model is cached and sent to the aggregator.
Ready to get started? Great! Click here for Quickstart.